В тази статия ще разгледам нужната теория, за да може човек, който си е направил WGS тест, да разбере каква информация му дава той и да го подготви да интерпретира резултатите. Тук се обясняват базови термини, които са нужни за тази цел.
За съжаление след разбирането на всичко тук, се налага още една стъпка. Тя е конвертиране на информацията от лабораторията (поне от Dante Labs), защото резултатите не са във вид, директно готов за интерпретация. Това е обяснено в следващата статия от поредицата. Тя е на английски, защото вероятно ще е полезна на много други хора по света, извън контекста на този сайт. Освен това, който има познанията да направи описаното в нея, 100% знае и английски.
Съдържание
Поредица „гени“
Тази статия е част от цяла поредица. Ето всички части, подредени хронологично и логически една след друга:Психиатричен генетичен тест
Генетично изчитане на целия геном
Теория на генетичния анализ
Analyzing your genome
Интересни гени
Внимание
Може на моменти терминологията ми да не е точна и със сигурност съм допуснал много грешки и неточности. Вероятно защото не съм лекар, не съм учил медицина, не съм учил биоинформатика, нямам контекст и не претендирам в никакъв случай за достоверност и изчерпателност. Ако ме хване човек, който ври и кипи в темата, вероятно ще ме направи за смях. Също така нямам времето и ресурсите да задълбая колкото ми се иска, защото имам други приоритети в живота си. Въпреки това, съм прекарал страшно много време, за да разбера дори базови неща. Споделеното тук е най-доброто, на което съм способен, без претенции. Генетиката е много, много сложно нещо, което съм се опитал безкрайно да опростя и което самият аз не разбирам изобщо добре.
Силно опростявам доста сложна тема, за да вместя статията в разумен брой думи и да остане все пак четима и разбираема. Вероятно съм допуснал множество грешки. Извинявам се предварително. Моля който реши, да ме поправи. С удоволствие ще внеса корекции.
ДНК
Вашето ДНК е вашият сорс код. Това е кодът, който ви описва като индивид от вид homo sapiens. Вътре са всички инструкции (рецепта) за вашето „производство“. ДНК е глобален програмен език за всички живи организми на тази планета. Може да не ви харесва особено, но вие сте просто един био робот. Същият програмен език, но с други инструкции в ДНК молекулата, води до произовдството на куче, орех, маймуна, зрънце грах или пшеница.
Структура
ДНК е една много дълга последователност от 2 преплетени вериги с множество позиции по тях. На всяка позиция имаме буква, която я описва. Буквите не са като в нашата азбука (А-Я), а са само 4. Изреждам на латиница: adenine (A), cytosine (C), guanine (G), thymine (T). Винаги в едната верига буквата A съответства на буквата T в другата верига. Винаги в едната верига буквата G съответства на буквата C в другата верига. Всяка двойка букви (бази) между двата оплетени реда в книгата нарича нуклеотид.

Няма да навлизам в подробности защо ДНК има 2 вериги, вместо само една. Приемете втората като „резервно копие“.
Когато сте били създадени, сперматозоидът от баща ви е носил копие от цялата негова дълга ДНК верига (сама по себе си двойно преплетена). Яйцеклетката от майка ви е носила нейното копие (сама по себе си двойно преплетена). При създаването ви, двете се комбинират. Съответно всяка една ДНК молекула във всяка една ваша клетлка има дъъългата двойно преплетена ДНК верига от баща ви и дъъългата двойно преплетена ДНК верига от майка ви.
Тъй като наведнъж дължината би била умопомрачителна, природата я е разделила в хромозоми. Това са нещо като глави на книга. Хората имат 23 хромозома (не е точно така, но няма да навлизам в подробности). И ако трябва да съм още по-точен, във всеки хромозом имате множество позиции (букчивки) от мама и още толкова от тате.

Ето пример как изглеждат първите 12 хромозома. Едната част е от майка ви, другата от баща ви, а вътрешно всяка от тях е двойно преплетената поредица от бази с букви.
Бананът да кажем има само 4 хромозома – генеичният му материал е доста по-малко.
Във всеки един хромозом имаме множество позиции. Да взимем за пример позиция 19963748 в хромозом 22. На нея на ДНК-то на мама имаме дадена буква на едната верига (и единствената възможна друга на огледалната). По същия начин на същата позиция имаме буква от ДНК-то на тате (и единствената възможна на огледалната).
В контекста на една от веригите, имаме една буква. В контекста на двойката преплетени вериги, имаме нуклеотид. Това е хоризонталната връзка по-долу между буквите A<->T и G<->C.
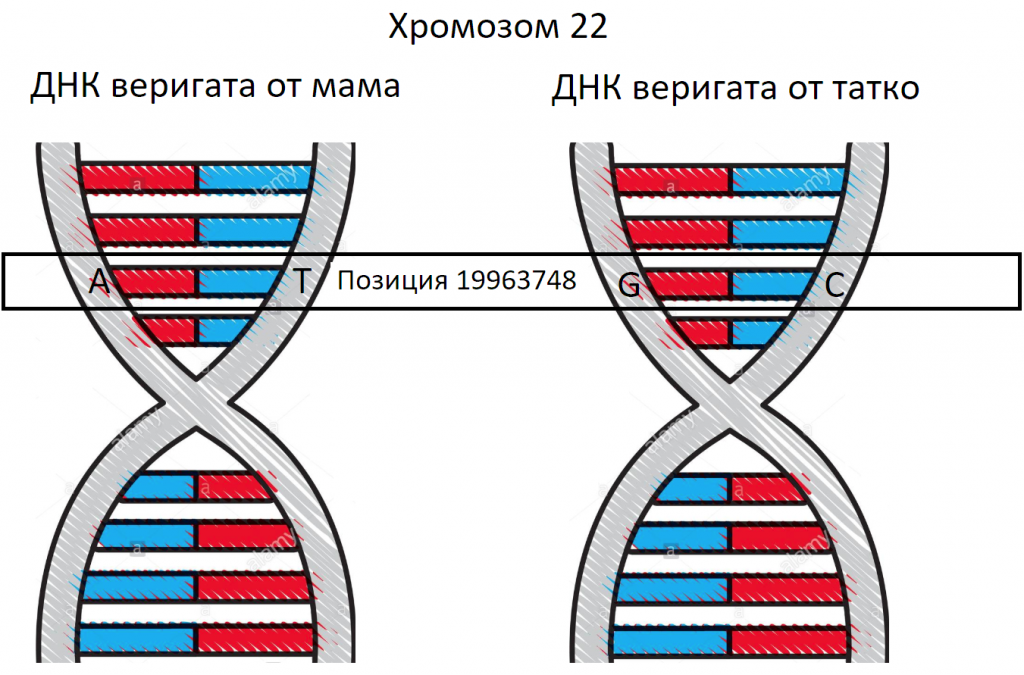
Да разбера и осъзная описаното в тази картинка по този начин ми отне години. То беше ключово, за да мога да построя в главата си работещ генетичен модел и да завърша цялата поредица от статии, започнати още през 2018-та. Случи се на ден, който няма да забравя – 17 май 2020 година.
Гени
Както вече научихме, ДНК-то е съставено от две двойнопреплетени вериги (от мама и тате), разделени в 23 хромозома. Част от него са важни и съдържат гени, части от него условно казано не са, защото не съдържат гени.
Какво е ген? Поредица букви (нуклотиди, ако погледнем всъщност връзката между двете вериги) на дадена позиция в даден хромозом до друга позиция в този хромозом. В даден хромозом има множество гени, както и можество поредици от букви (нуклеотиди), които не попадат в ген. Всеки ген си има име. Например „COMT“. Един ген кодира един протеин (няма да задълбавам това какво е). Има около 22 000 гена и те определят цвят на очите, ръст, функция на различни органи, предразположеност към инфаркт, инсулт, затлъстяване, тревожност или депресия и т.н.
Референтен геном
Тъй като ДНК-то на всички хора има доста малко разлики и 99% е еднакво, е удобно да имаме един образец и да описваме само разликите в ДНК-то на даден човек спрямо образеца. Този образец се нарича „референтен геном“.
Той се състои от комбинация от ДНК на няколко доброволеца, дали генетичния си материал. Научната общност е го е приела за отправна точка и се интересува само от разликите между даден човек и този образец.
Съществуват версии.
Например деветнайстата поредна е от 2009 година, нарича се GRCh37 (наричана по друг стандарт hg19), а от 2013 година е последната до момента версия – GRCh38 (наричана по другия стандарт hg38). За удобство взимайки ДНК-то на даден човек, пазим само разликите спрямо някоя версия на референтния геном (напоследък GRCh37 или GRCh38), като посочваме кой. Отделен въпрос е, че всяка версия има подверсии (пачове), но да не задълбавам.
Така информацията е много, много по-компактна. Ако да речем група учени изследват 100 човека, те имат на хард диска си само веднъж целия референтен геном (100GB+) и 100 пъти само разликите за всеки отделен човек (примерно по 150MB).
Мутации
Както казахме, ДНК-то на различните хора се различава леко. Иначе всички щяхме да сме 100% еднакви, а това очевидно не е така. Мутациите се основният механизъм в природата за развитие. Може да се случат в следствие на радиация, на влияние на околната среда, както и като „грешка при преписване“ от ензимите, които разплитат двойносвързаната верига в ДНК-то на двамата родители и я „преписват“ буква по буква, създавайки вас.
Така работи еволюцията. Някои грешки са за добро и съществото или растението получава нови, по-добри дарби. Ако това същество или растение оцелява по-добре, „грешката“ оцелява в годините (предава се на все повече деца) и става новото „нормално“. Ако грешката е за лошо, съществото или растението получава „бъг“, който му пречи да оцелее по-добре и постепенно „бъгавите“ не оцеляват, не предават грешката и тя се заличава.
На всяка една позиция в ДНК приемаме за „нормална“ буквата от референтния геном (в контекста на една от двете вериги). Всяка различна наричаме алел (allele) – алтернативна „версия“ или „вариант“ на тази позиция. В случая имаме две значения на нормална в зависимост от контекста. Тук може да греша, моля да бъда поправен ако е нужно.
Контекст 1: Статистически повечето от населението (от дадена раса все пак) ще има преобладаващо дадена буква на дадена позиция в даден хромозом. Когато тези проценти са значителни, приемаме тази „версия“ на ДНК-то като „нормална“. Внимание – за друга раса може тези стойности да са различни. Така имаме „нормални“ (в смисъла на преобладаващи) букви според раса.
Контекст 2: Тъй като референтният геном все пак е от живи хора, които на някои позции нямат преобладаващата буквичка, която имат повечето хора от тяхната раса, те на места ще имат „ненормална“ буква. Въпреки това, понеже ги използваме за референция, сравнявайки се спрямо тях, приемем буквата на тази позиция в генома като „златния стандарт“ от гледна точка на файловете, с които се описват разликите от човек до човек.
Важно! Не забравяйте, че навсякъде, където казвам позиция, имам предвид следното: в контекста на едната верига ще е дадена буква. В контекста на огледалната верига, ще е единствената възможна огледална буква. Освен това имаме една възможна двойка в ДНК-то от мама и друга (същата или различна) в ДНК-то на тате. Повече по темта – в следващата точка.
SNP, INDEL, SV, CNV
До тук говоря за една сбъркана буква на дадена позиция. Такава мутация се нарича SNP – Single-nucleotide polymorphism. На български се чете снип. Това е разменена буква (+ огледалната) на дадена позиция. Нали помните: цялата връзка между буквите от двете вериги на една позиция се нарича нуклеотид. Т.е. полиморфизъм (вариация) на нуклотид. От там и името.

Това са най-честите мутации.
Друг вид са INDEL – INsertion / DELetion. Т.е. може вместо дадена буква да е разменена, няколко други да са вмъкнати или липсващи, изместващи цялата верига след тях с няколко позиции. SV мутациите са подобни, просто в много по-големи размери.
Друг вид са CNV (Copy-number variation), при който дадена поредица е копирана два пъти.
Със сигурност INDEL/CNV също са интересни, но най-интересните и най-добре изучени и предмет на цялата поредица статии са SNP мутациите.
SNP мутациите в детайли
Когато на дадена позиция повече от 1% от населението има вариация в буквата, официално това се приема за често срещана вариация и тя се нарича SNP (снип).
За всяка позиция, както казахме, имаме референта стойност. Златният стандарт. Но ако сте чели внимателно, вероятно сега се сещате, че на всяка позиция (loci) имаме една двойка букви от мама и една от тате. Или общо 4 букви. Показвам отново илюстрацията:
Рефентният генеом версия GRCh38 казва, че в хромозом 22 на позиция 19963748 референтата буква е G, но както виждаме в реалността имаме точно 4 букви. Как има смисъл това?
Честно казано да разбера точно това ми отне абсурдно много време. Споделям.
Първо „конвертираме“ до една от веригите. T=A, G=C. След това идва интересният момент. Имаме няколко комбинаци:
- Може веригата от мама да е същата като референтната, както и тази на тате. Тогава казваме, че нямаме мутация.
- Може едната от двете вериги да е еднаква с референтанта, а другата (от единия родител) да не е. Тогава имаме хетерозиготна мутация. Хетеро=различен.
- Може и двете вериги и от двамата родители да са различни от референтната. Тогава имаме хомозиготна мутация. Хомо=еднакъв.
Как да интерпретираме този случай? Просто. При референта буква G, виждаме че едната от двете букви на веригата от татко е G. Но веригата от мама няма G.
Следователно имаме хетерозиготна мутация.
Или казано по друг начин ако референтана двойка букви от едната верига на мама и тате е (G;G), то нашето ДНК на тази позиция е (A;G). Третата възможност би била (A;A).
Комбинацията, изписана по този начин, се нарича генотип.
От генотип през снип до изводи
Всеки един снип е описан в една голяма база данни. Направени са много научни изследвания и нови се правят всеки ден. Те малко по малко откриват зависимости. Казано по много прост начин – ако за снип Х вие имате тези и тези букви, то това значи това и това. Ако имате други, значи нещо друго за вас.
След като разберем по данните от генетичното изследване какъв е нашият генотип на даден снип, отваряме сайт като SNPedia и интерпретираме. Всеки снип си има уникален номер в базата данни. Ето примерен SNP: RS4680.

Вижте информацията: референтен геном GRCh38, пач версия 1, версия на SNP базата данни 141, хромозом 22, позиция, 19963748, SNP номер RS4680.
Генотип (A;A): притесняващ се (паникьор, вечно премислящ)
Генотип (A;G): някъде по средата
Генотип (G;G): войн (устойчив на стрес)
Точно в SNPedia няма информация коя е референтната буква за дадена раса (после ще ви покажа други места), но аз знам, че в случая за европеидната раса тя е G. Т.е преобладаващото население по този критерий е конфигурирано от завода устойчиво на стрес, а по-малка част от хората (като мен, аз имам генотип A;A), не е устойчиво на стрес.
Вижте линка към SNPedia. След това вижте точно 300-та научни изследвания (да, 300), всяко от които вади изводи от тествани хора на база на този снип. Той е доста известен и е свързан с нивата на допамин в предната част на мозъка и по-точно ефективността (скоростта) на един ензим, който го разгражда.
Сайтове за интерпретация
Съществуват сайтове, в които може да качите файла с вашите генетини данни, след което те разчитат вашия генотип за всеки снип и ви показват информацията в удобен вид. По-нататък в поредицата ще ви покажа как да подготивте този файл ако сте си направили тест, както и как сами да си разчетете генотипа за всеки снип от самия файл без да плащате на сайт за това.
И все пак в сайтовете е по-удобно, защото имате удобен интерфейс от едно място, а и подреждат информацията в изключително удобен вид за анализиране, вместо да я четете от текстови файлове.
Много добър сайт е SelfDecode. Ето какво ще ни каже той за същия снип: RS4680.

Име на ген: COMT, важност 5 (най-високата), по-малко разпространен алел (вариант на буквата) А, по-разпространен вариант на буквата G. Рисков алел (неблагоприятен): A.
Съответно най-добре сте при GG, някъде по средата AG и най-кофти е АА. Е, изтелил съм късата клечка.
Забележете – този сайт ви дава възможност да качите генетичен файл, след което той анализира вашия генотип и го показва в секцията „My Genotype“. Кликнете на линка в SelfDecode и само вижте за колко информация става дума. Изредени са един куп предимства и недостатъция за двата варианта (технически са 3 де), а най-долу има разпределението по това кой вариант колко често се среща във всяка раса.
Друг подобен сайт на SelfDecode е Promethease. Качвате файл (който ще ви науча как се създава от данните от лабораторията) и готово. Сайтовете дори ви показват най-важните неща за вас. Кликвате, разглеждате, вадите си изводи. Цената към момента е $12. Promethease генерира база данни (offline Javascript страница с различни филтри), в която може да ровите и да направите връзка между известните до момента снипове (SNPs) и вашия конкретен генетичен код. След това отивате в SNPedia и си четете каквото искате да знаете за всеки снип.
Ето например как изглежда същият снип в Promethease, но тук е с генетичен материал от друг човек, който има генотип (A;G), т.е. „по средата“:

Съответно сайтът разчита по качения файл в профила ви, че вие имате генотип (A;G) – хетерозиготна мутация от златната буква G, а линкът води към SNPedia, където да видите какво пише за вашия генотип.
И двата са платени. Аз съм си платил и за двата, но към момента на писане на статията нямам качени файлове, защото преминах през един куп препятствия, които на вас ще ви бъдат спестени.
Трети много полезен сайт е sequencing.com. Там положението е малко по-различно. Това е платформа за генетични приложения. Там качвате веднъж генетичните си данни в профила си и след това си купувате различни приложения, които работят върху тях, анализирайки ги и правейки доклади. Например Dante Labs ви дават един безплатен доклад от едно от най-известните приложения там. За това – четете по-долу.
Генотип и фенотип
Генотип е това, което ви е заложено генетично по даден критерий. Фенотип е това, което се е проявило. Разликите идват предимно от средата, в която организмът е израснал. Сещам се за нереалистичен пример – може като генотип да имате висок ръст, но от дете да вдигате тежести и плувате, което да компресира гръбначния ви стълб, което да доведе до фенотип нисък ръст. Или да имате генотип да сте дебели, но да се храните здравословно, много да спортувате и като резултат фенотипът да е слаба фигура.
Някои от сниповете (вашата генетична конфигурация) имат 1:1 отражение във фенотипа (видимите резултати). При други това не е така или е трудно това да се определи. Голяма част от сниповете не са изследвани добре или изследванията дават противоречиви резултати. Аз съм разгледал около 300 снипа за себе си до момента и за някои определено резултатите не са верни, докато за други са. Това е така, защото не всеки снип е еднакво изследван и корелацията генотип-фенотип е толкова директна.
Интерпретация от лаботорията
Когато си направите WGS тест, лабораторията ви дава доста подробен доклад по някои от добре известните и изследвани мутации. Dante Labs включват безплатен доклад от приложението Wellness and Longevity в sequencing.com, за който говорих по-горе. Получавате го в пакет с резултатие от теста, като това приложение иначе струва $69 към момента. Ето примерен доклад.
Подготовка на резултатите
След като си направите теста и резултатите дойдат, трябва да изпълните разни трансформации върху тях. В следващата статия от поредицата ще обясня как. На английски е, защото може да е полезен и на хора от други националности. Като резултат получавате един много голям текстов файл.
С този файл ще имате вашия генотип за всеки един снип. Така ще можете директно да гледате безплатно без регистрация и плащане в SelfDecode и SNPedia какво значи това за вас. Също така може да го качите в SelfDecode или Promethease, да платите скромна цена и да навигирате много удобно. Сайтовете също така ви посочват директно важни, полезни или опасни мутации и правят удобно да им обърнете веднага внимание.
Заключение
Честно казано да разбера всичко, върху което базирах тази статия, ми отне ужасно много време и усилия. Нещата уж не са сложни, както са обяснени тук и изчетени за 15-на минути, но повярвайте ми – докато си направя модел в главата, положих умопомрачително много усилия.
Още по-трудно беше да разбера как да подготвя генетичния файл – процес, който съм описал в следващата статия. Е, струваше си.